大学生
最后登录1970-1-1
在线时间 小时
注册时间2017-6-23
|
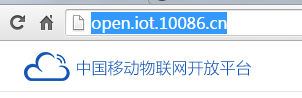
我们平常访问网页一般都是在浏览器里直接输入域名浏览器在收到服务器的返回之后再把这些内容呈现出来。下面我们以访问中国移动物联网开放平台的首页为例我们在浏览器地址栏输入它的域名

浏览器便会呈现下面内容

这是我们司空见惯的模式再往深入方面考虑浏览器究竟是怎样跟服务器通信的呢那就需要我们了解HTTP协议。
HTTP是Hyper Text Transfer Protocol协议的英文缩写是目前网页传输的通用协议。我们在浏览器输入域名的时候如果你省略了http://浏览器就会自动帮你加上不过有时候你看不见比如在chrome浏览器里你看到的便是这样
你复制/粘贴试试看看有什么不同。
HTTP协议采用请求/响应模式有的地方也叫请求/应答模式都是一回事英文都叫Request/Response永远都是客户端主动先发起请求服务器做出响应再返回给客户端如下图所示

HTTP协议是无连接、无状态协议一次请求/响应完成之后客户端与服务器之间的连接便会关闭也不保持连接的状态信息因此后续的请求/响应跟前面的一点关系也没有这样便于服务器快速响应。
请求模式
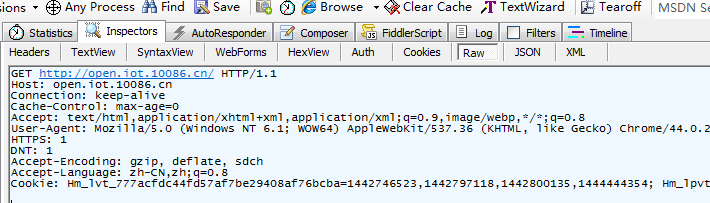
我们用网络调试工具Fiddler再看看刚才浏览器在后台向服务器发送了些什么
- GET http://open.iot.10086.cn/ HTTP/1.1
- Host: open.iot.10086.cn
- Connection: keep-alive
- Cache-Control: max-age=0
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
- User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/44.0.2403.69 Safari/537.36 QQBrowser/9.1.4060.400
- HTTPS: 1
- DNT: 1
- Accept-Encoding: gzip, deflate, sdch
- Accept-Language: zh-CN,zh;q=0.8
- Cookie: Hm_lvt_777acfdc44fd57af7be29408af76bcba=1442746523,1442797118,1442800135,1444444354; Hm_lpvt_777acfdc44fd57af7be29408af76bcba=1444608682
这些就是刚才浏览器向服务器发送到请求数据包含了客户端请求中包含请求的方法、URI、协议端信息、内容等它们之间用空格隔开。我们概括一下HTTP请求一般由3部分组成
其中消息报头和请求正文不是必须的跟请求的方法有关。注意每行都以CRLF结尾。
请求行
格式GET http://open.iot.10086.cn/ HTTP/1.1
GET是方法意思是向服务器请求把后面地址的内容发过来紧跟在最后的是请求采用的HTTP协议版本号。
其它常用的方法还有POST, PUT, DELETE等等我们后面用到再讲。
消息报头
我们以上面的例子来讲解注意每一个报头域的格式为 报头名字+“”+空格+值+CRLF 写程序的时候别忘了这个不显眼的空格而且不同操作系统对后面的回车换行符的理解不一样最好是显式的使用CRLF要知道调试错误可比你省略这几个字符费时费脑多了。
Host必须用来指定被覌定被请求的资源的internet主机和端口不要问我为什么上面请求行里已经有了为什么这里还必须重复一遍我也不知道标准答案。
Connection我们前面说了HTTP协议是无连接、无状态协议一次请求/响应完成之后连接就会断开这对客户端而言有点小麻烦每次请求之间都要重新建立一次连接时间开销可能不小要是能利用上次请求的连接多好。所以这里允许你设置keep-alive如果服务器支持的话便可以在上次请求/响应完成之后接着用原先的连接如果设置成close或者服务器不支持keep-alive那只好老老实实的重新连接咯。
Cache-Control缓存指令一般不用理会。
Accept告诉服务器客户端支持哪些文件格式比如Accept: image/gif表示客户端可以接受gif图片Accept: text/html表示客户端希望接收html文本。我一般在单片机处理的时候都是用Accept: */* 反正它只负责接收呈现的活儿不归它管。
User-Agent告诉服务器你用的是什么操作系统、语言、浏览器以及版本号等毕竟不同的浏览器对相同的html文档的呈现方式都不太一样服务器知道之后尽可能让它们尽可能表现的一致当然这也得服务器支持才行。
其余几个几乎可以望文生义就不多讲。当然不同方法对Header的要求也不一样后面遇到再讲。
响应模式
上面讲的是请求的消息结构服务器响应的消息结构跟它类似。我们在浏览器里看到的是图文并茂的形式其实浏览器从服务器那里收到的都是一些html文本只是浏览器帮我们翻译成人类愉悦的方式而已。下面我们在fiddler里看看服务器返回的内容究竟是啥。
打开fiddler的response窗口就能看到
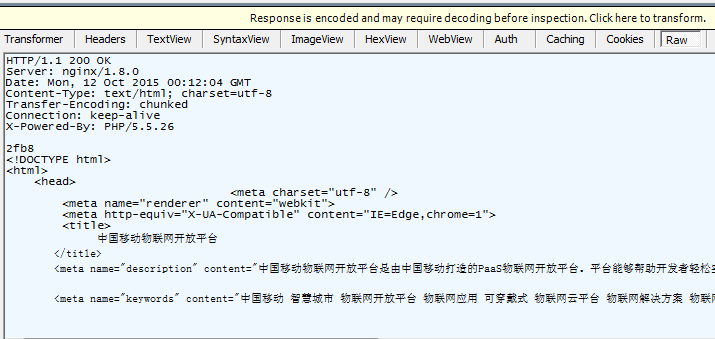
这是raw格式可以发现跟请求的数据包结构差不多也是可以分为三个部分
复制代码
同样道理服务器返回的响应消息中实际结构跟请求方法有关。
第一行就是状态行先是说明HTTP协议的版本接着是状态代码收到200 OK表示请求已经被成功接收。注意这个只表示通信成功你请求的内容是不是被正确执行还不一定这里一定要注意即使是返回200 OK也只表示服务器已经成功收到客户端的请求但是请求因为各种原因没有被服务器接受它在其它地方有提示响应状态为false这个要留心。
跟请求的消息结构一样响应报头跟响应正文之间也用一个空白行隔开。具体内容可以自己去看或者网上找找相关的资料。
|
|




 发表于 2017-7-6 10:38:03
发表于 2017-7-6 10:38:03
 提升卡
提升卡 发表于 2017-7-7 11:24:09
发表于 2017-7-7 11:24:09